We present Platypus a family of fine-tuned and merged Large Language Models (LLMs) that achieves the strongest performance and currently stands at first place in HuggingFace's Open LLM Leaderboard as of the release date of this work. In this work we describe (1) our curated dataset Open-Platypus, that is a subset of other open datasets and which we release to the public (2) our process of fine-tuning and merging LoRA modules in order to conserve the strong prior of pretrained LLMs, while bringing specific domain knowledge to the surface (3) our efforts in checking for test data leaks and contamination in the training data, which can inform future research. Specifically, the Platypus family achieves strong performance in quantitative LLM metrics across model sizes, topping the global Open LLM leaderboard while using just a fraction of the fine-tuning data and overall compute that are required for other state-of-the-art fine-tuned LLMs. In particular, a 13B Platypus model can be trained on a single A100 GPU using 25k questions in 5 hours. This is a testament of the quality of our Open-Platypus dataset, and opens opportunities for more improvements in the field.
Background
Our research focuses on optimizing LLMs using PEFT and LoRA with our curated dataset, Open-Platypus. This is set against the backdrop of rapid advancements in LLMs, from the introduction of massive models like GPT-3 to task-specific ones like Galactica. While models like OpenAI's GPT-3.5 and GPT-4 have set high standards, recent developments include models like TII's Falcon and Meta's LLaMa as open-source alternatives. The challenge lies in fine-tuning these models efficiently. Our approach aims to harness the benefits of dataset distillation and instruction tuning, ensuring enhanced performance while emphasizing domain-specific knowledge.
Contributions
Our results reveal that domain-specific datasets enhance performance in selected tasks. When combined with merging, this significantly cuts down training duration. Key contributions include:
Open-Platypus: A curated dataset derived from 11 open-source datasets, primarily focusing on enhancing LLMs' STEM and logic proficiency. Predominantly composed of human-crafted questions, with only about 10% generated by an LLM, Open-Platypus enables robust performance with minimal fine-tuning time and cost.
Dataset optimization: We detail our similarity exclusion approach, which helps in downsizing our dataset and minimizing data redundancy.
Addressing contamination: An in-depth exploration of the contamination issue in open LLM training sets, highlighting our data filtering process to circumvent this challenge.
Fine-tuning and merging: An overview of our selection, merging, and fine-tuning processes for LoRA modules, drawing inspiration from existing methodologies.
Open-Platypus
We release Open-Platypus to the public via Hugging Face.
Table 1: Datasets, Licenses, and Number of Leaked Questions. *The datasets marked with asterisks were not added to Open-Platypus but we include them because we ran contamination checks when considering which models to merge.
Our methodology prioritizes preventing benchmark test questions from leaking into the training set to avoid biasing results through mere memorization. While we strive for accuracy, we recognize the need for flexibility in marking questions as duplicates, given the varied ways a question can be posed and the influence of general domain knowledge. To manage potential leaks, we crafted heuristics for manually filtering questions from Open-Platypus with over 80% cosine embedding similarity to benchmark questions. We classify potential leaks into three categories: (1) duplicate (2) gray-area and (3) similar but different. To err on the side of caution, we exclude all groups from our training set.
Duplicate
These are near-exact replicas of test set questions, with perhaps a minor word change or slight rearrangement. This is the only category we count as "true" contamination, as defined by the number of leaked questions in the table above. Specific examples of this can be seen in:
Figure 1: Examples of true contamination.
Gray-area
The next group, termed gray-area, encompasses questions that are not exact duplicates and fall within the realm of general knowledge. While we leave the final judgement of these questions to the open-source community, we believe they often necessitate expert knowledge. Notably, this category includes questions with identical instructions but answers that are synonymous:
Figure 2: Examples of gray-area questions.
Similar but different
These questions have high similarity scores but differ significantly in answers due to subtle question variations. Please see the paper for detailed examples.
Fine-tuning & Merging
After refining our dataset, we center on two methods: Low Rank Approximation (LoRA) training and Parameter-Efficient Fine-Tuning (PEFT) library. Unlike full fine-tuning, LoRA preserves pre-trained model weights, integrating rank decomposition matrices in transformer layers. This cuts down trainable parameters, saving on training time and cost.
Initially, our fine-tuning honed in on attention modules like v_proj, q_proj, k_proj, and o_proj. Later, based on insights from He et al., we transitioned to gate_proj, down_proj, and up_proj modules. These showed better results except when trainable parameters were less than 0.1% of the total. We applied this uniformly to both our 13B and 70B models, which resulted in 0.27% and 0.2% trainable parameters. The only variance was the initial learning rate between these models. For an in depth breakdown of our pipeline, pleaase refer to the paper.
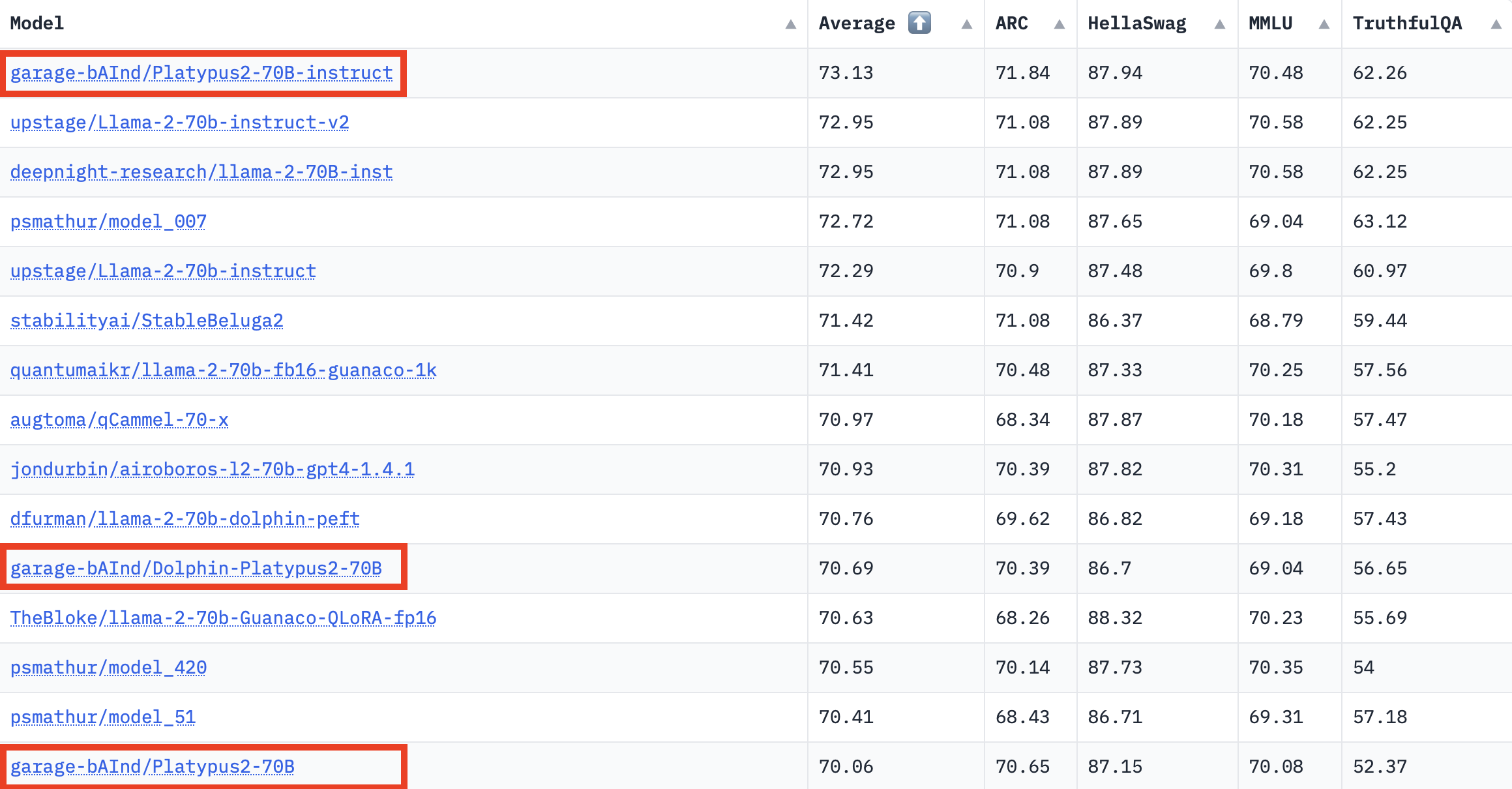
Results
Hugging Face Open LLM Leaderboard as of 8/10/23.
Limitations
Platypus, as a fine-tuned extension of LLaMa-2, retains many of the foundational model's constraints and introduces specific challenges due to its targeted training. It shares LLaMa-2's static knowledge base, which may become outdated. There's also a risk of generating inaccurate or inappropriate content, especially with unclear prompts. Although Platypus is enhanced for STEM and logic in English, its proficiency in other languages is not assured and can be inconsistent. It may occasionally produce content that's biased, offensive, or harmful. Efforts to mitigate these issues have been made, but challenges, especially in non-English languages, remain.
The potential misuse of Platypus for malicious activities is a concern. Developers should conduct safety testing tailored to their application before deployment. Platypus may have limitations outside its primary domain, so users should exercise caution and consider additional fine-tuning for optimal performance. Users should ensure no overlap between Platypus's training data and other benchmark test sets. We've been cautious about data contamination and have avoided merging with models trained on tainted datasets. While we are confident there is no contamination in our cleaned training data, it is unlikely but not impossible that some questions slipped through the cracks. For a comprehensive understanding of these limitations, please refer to the limitations section in the paper.
BibTeX
@article{platypus2023,
title={Platypus: Quick, Cheap, and Powerful Refinement of LLMs},
author={Ariel N. Lee and Cole J. Hunter and Nataniel Ruiz},
booktitle={NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following},
year={2023}
}
Acknowledgements:
A very special thank you to both Hugging Face, for creating a space where anyone can evaluate and release LLMs, and Meta AI for sharing LLaMa-2, the backbone of our fine-tuned models. We would also like to thank the creators of LoRA, without whom we could not have afforded to fine-tune a 70B variant of LLaMa-2. This was a fun learning experience made possible through the open-source community.